
Curated datasets are available on the internet for you to use in portfolio projects. This blog post was intended for our mentoring program, but anyone can benefit! I’ve separated the datasets into “health-related” and “non-health-related” and put them in alphabetical order by their abbreviation. I’ve also included some of my own personal notes based on what I have experienced from working with the dataset or others who have used it.
To provide you curated datasets, I will keep adding to this post as I learn more about these datasets, and find out about other datasets you can use for your portfolio projects. If you have any comments about your experience with these datasets, please add them to this blog post! Good luck with your projects!

Formal name: Behavioral Risk Factor Surveillance System
Description: Cross-sectional annual dataset of an anonymous phone-based health survey in the United States (US).
Pros:
- Well-documented
- Datasets free to download online
- Some extremely useful questions for analysis
- Goes many years back so trending possible
- Core dataset includes representative sample of US population by states and nationally, including weights for weighted analyses
- Large (over 400,000 records)
Cons:
- Some outdated questions
- Lack of contemporary questions (e.g., e-cigarette use)
- Cross-sectional, so cannot be used for longitudinal studies
- Recent severe reduction in core questions asked (as of 2020)
- Lacks clinical data or data that can be measured in-person (see NHANES)
Resources:


Formal name: Center for Medicare and Medicaid Services (CMS) in the United States is public insurance. Pharmacy-related data are available online.
Description: CMS has some different online dashboards where you can look at a tabular version of the pharmacy data, do filters, and download the raw data for analysis.
Pros:
- Very easy to browse and download data using the dashboards
- Well-documented
- Up-to-date
- Even if you do not have a background in pharmaceuticals, it is easy to look up information about drugs, the US, and other topics to be able to come up with a question to answer using some of these data.
Cons:
- The data served up are not necessarily the data you want. There are calculated variables that apparently have to do with seeing if a policy is met that are not useful generally for analysis (e.g., counts of people aged 65 and over receiving a drug vs. everyone).
- Even though it is easy to acquire the domain knowledge necessary to do an analysis, it is quite consuming. Drugs are complicated, Medicare and Medicaid are complicated, and US healthcare finance is also complicated.
Resources:
- If you click on Access Cost Data button, you will go to a page that will provide you links to four different pages: Medicare Part B Spending by Drug, Medicare Part D Spending by Drug, Medicaid Spending by Drug, and Medicare Part B Discarded Drug Units. On each of these pages, if you choose the “view data” button in the upper left, you will be brought to the dashboard to filter and download data.

Formal name: Diabetes Control and Complications Trial (DCCT) and Epidemiology of Diabetes Interventions and Complications Study (EDIC)
Description: The DCCT was originally a study of Type I diabetics who were trying to actively control their diabetes, and then EDIC was longitudinal follow-up that was done on this cohort. I have not used this dataset so I’m basing my opinions on the documentation.
Pros:
- Well-documented
- This is a very high-quality dataset. The measurements seem very valid and reliable.
- Very long-term follow-up, so survival analysis models can be used
- For the entire trial the sample size is pretty big, and the data appear to be pretty clean.
- Datasets are available at no cost but you must undergo authorization
Cons:
- Very old-fashioned dataset and structure. Non-relational, so very confusion.
- Documentation page has all necessary information, but is clumsy, slow, and labyrinthian.
- Need a lot of domain knowledge to understand the dataset. Measurements such as psychological instruments, labs, and genetics require advanced knowledge to analyze.
Resources:
- I review the DCCT and EDIC datasets in my online course, “How to do Data Close-out: Boot Camp”.


Formal name: United States Food and Drug Administration (FDA) Adverse Event Reporting System
Description: In the United States, after a drug goes on the market, if people have adverse events, it can be reported into this system.
Pros:
- Date are current and up-to-date
- Easy to download in ASCII format free over the internet
- Well-documented – zip file contains explanation of each dataset
- Although somewhat confusing, it is not that challenging to understand the data from the point-of-view of domain knowledge
- Very nice dashboard available to help you understand the data before you download it.
Cons:
- Data are biased, in that many adverse events go unreported
- Data need to be aggregated to be meaningful. For example, if you want to study “Lisinopril”, or “hypertension medication”, or certain classifications of adverse events, you will need to look at all the different formulations and develop classifications.
- Multiple tables, so it will take some reading of documentation to figure out what you want to do with this dataset
- No load code posted
Watch our livestream recording for a demonstration of how to query the public FAERS dashboard.

Formal name: Healthcare Cost & Utilization Project
Description: Cross-sectional annual datasets of a sample of data from United States (US) healthcare settings intended for analysis to understand healthcare use and cost. There are multiple databases, but the most popular is the Nationwide Inpatient Sample (NIS), which is an annual dataset of data about patients being discharged from US hospitals. The pros and cons below refer specifically to the NIS, as I have little familiarity with the other datasets.
Pros:
- Well-documented
- Goes many years back so trending possible
- Includes rare cost-related data so can be used for healthcare cost forecasting
- Includes many calculated variables based on economics that are useful in forecasting models
Cons:
- Datasets are for sale, and although prices are not that high, it takes a lot of research on their documentation web site to figure out what data you want to purchase
- Due to lack of access in the US healthcare system and other features of US healthcare financing and delivery, the dataset is unbalanced and biased, and it is hard to use for health-related analyses. In fact, drawing inferences may actually perpetuate bias in the US healthcare system.
- Many variables in the dataset are very hard to understand. They require knowledge of both the healthcare setting as well as healthcare economics.
- Data prepped for SAS, but not open source applications
Resources:
- I review HCUP documentation in my online course, “How to do Data Close-out: Boot Camp”.


Formal name: Military Health System Data Repository
Description: This repository is a data lake of processed production data from healthcare settings in the United States (US) military.
Pros:
- Extremely well-documented and well-used
- Goes many years back so trending possible
- Analyses extremely helpful to the functioning of the US military
- Servicemembers and veterans who want to do epidemiologic analyses: These are GREAT datasets for you, because you will already understand them, and will have less trouble getting access to them for projects
Cons:
- Requires a lot of domain knowledge. If you have not worked for the military or been in the military, these will be very confusing datasets for you.
- Difficult to get permission to access unless part of a research team that has approval. A good way to address this is to become part of a research team that gets a grant from the military or other organization to use these datasets to study the military.
Resources:
- My colleagues and I published some injury papers where we combined the SIDR and SADR datasets from the MHS with other military datasets: one on ankle injury, one on knee injury, and one on rhabdomyolysis.

Formal name: National Health and Nutrition Examination Survey
Description: Cross-sectional annual dataset of an in-person health survey in the United States (US).
Pros:
- Datasets free to download online
- Some extremely useful questions for analysis
- Goes many years back so trending possible
- Population-based sampling with weights
- Includes rare in-person examination data, such as oral health data, and anthropometrics.
- Also includes some laboratory measurements, and other hard-to-measure health data.
Cons:
- Some outdated questions
- Lack of contemporary questions (e.g., e-cigarette use)
- Cross-sectional, so cannot be used for longitudinal studies
- Dataset is small (<10,000 per year). For a larger health survey with similar measurements, see BRFSS.
- Extremely fragmented dataset, in that each exam or questionnaire is stored in its own dataset, so hard to put together a dataset with all the covariates needed about every experimental unit. For this reason, many researchers aggregate multiple years of NHANES data to answer research questions.
- Data prepped for SAS, but not open source applications
Resources
- In this blog post, I show you an example of shopping for variables in the different NHANES tables, and evaluating selection bias as you add variables.
Watch our livestream recording for an introduction to the NHANES documentation and guidance for downloading and using the data.


Formal name: Medical Expenditure Panel Survey (MEPS) Data Files
Description: The United States conducts the MEPS, which is a set of large-scale surveys about families and individuals, their medical providers, and employers. The focus of MEPS is cost of healthcare, use of healthcare, and health insurance coverage.
Pros:
- The MEPS has very large datasets that are on different topics (because they are surveys). They are done on different samples about different topics at different times.
- The MEPS can be connected to other files such as public use files (PUF) to make them more useful (e.g., to do trending over time).
- You can download the data directly from the web site in SAS and other formats.
- There are excellent codebooks and lots of data documentation.
- Researchers use the MEPS data for peer-reviewed publications
Cons:
- Unfortunately, what we really are having a problem with in the United States is human health – not healthcare cost, utilization and insurance coverage. MEPS reflects mainly how badly the system is performing at meeting US health needs – so it’s not very satisfying to use.
- The files are huge and complicated. To use one file, you would need to do a lot of study and background documentation.
- The existing publications on the MEPS data try to overcome the limitations that it is not about human health, so it’s hard to use MEPS data to troubleshoot how to improve US health. Therefore, existing publications are kind of lame, actually, and it’s hard to follow their methods to produce a good report about another topic.

Formal name: National Survey of Children’s Health (NSCH)
Description: The United States Census started conducting this cross-sectional surveillance study of children aged 0 through 17 years in 2016. First, households are screened in-person, producing a “screening” dataset. Next, households are sent a “topic” survey based on the age of the child for the parents/guardians to fill out about the children. They can fill it out online or on paper and send it back.
Pros:
- Very large datasets each year (screening and topic are over 50k rows).
- National stratified cross-sectional sampling in the United States (including weights).
- Data available online back to 2016
- Trustable, updated and well-documented.
Cons:
- May be hard to estimate across entire child population because there are three topic questionnaires: T1 for age 0 to 5, T2 for age 6 to 11, and T3 for age 12 to 17
- Screening dataset doesn’t have a lot of different columns
- Requires quite a bit of background research before you can devise an analytic plan
- Not used as often in analyses so not a lot of precedent set
Resources:
- Background information from the Data Resource Center for Child & Adolescent Health
- History of the effort from the Health Services and Resources Administration (HRSA)

Description: Warranty Week is a newsletter for warranty management professionals. If you want to get into studying warranties (great for actuaries!), then this is the site for you. It has manufacturers’ product warranty expense reports available in an Excel spreadsheet format. Each spreadsheet includes warranty reserves, claims, and accrual figures for specific companies. Thanks to Joe Chantiny for turning me on to this data source!
Pros:
- Voluminous, accurate data from a trusted provider.
- It is easy to choose data from companies a la carte – so you can focus in a warranty domain (e.g., automotive, energy, manufacturing).
Cons:
- You need to have a lot of domain knowledge to understand this dataset and figure out what to do with it. If you want to know more, please contact Joe Chantiny on LinkedIn and he can give you more information.
- The spreadsheets are NOT tabular – each spreadsheet is essentially a report. To do anything with the data, you would have to process it into data tables.
- Data are not free, but the cost is low, and you can pay by PayPal. However, you need to shop carefully on the site to decide exactly what you are buying. They have 394 datasets, and as of this writing, to purchase all of them is less than $2,000, which is actually a great deal in my opinion.

Description: Massachusetts has three casinos, and each has its own revenue report that is updated monthly. Each revenue reports is in PDF format, and looks like an Excel table. Each row has data about each month the casino has been open.
Pros:
- If you are a casino customer, it is very easy to understand the data.
- Interesting to use in time trending, and could be useful if paired with casino data from nearby states to review competitive pressure as the different casinos in Massachusetts opened.
- Great examples of continuous variables and monetary data for practice.
- Opportunity to connect to other datasets about Massachusetts for richer information
- Portfolio projects can be very interesting, flashy, and easy to understand
Cons:
- Electronic datasets need to be developed – they are in PDF format. It is not hard to do data entry, but an enterprising programmer could scrape the data easily as well.
- Small datasets, so very little data. Casinos have not been open in Massachusetts very long.
- Only a few columns, so you need to be creative to develop research questions and analyses to answer them.
Resources:
- See my blog post for an example of a portfolio project I developed before the pandemic, so it is outdated now. Feel free to update it with your own analysis!


Description: Every 10 years, the US tries to do a census – meaning count everyone in the US. They have us all fill out a form – either a long form, providing a lot of data, or a short form, providing very basic demographic data. There is also a yearly survey called the American Community Survey that is done by phone to try to improve the biased estimates that come from the census (because not everyone can be contacted to fill out a form.
Pros:
- They have a new rebuilt portal (goodbye American FactFinder)!
- These data are very helpful when you are writing about a specific organization or location in the US. If I am analyzing data that came from students in a particular school, then I can use census data to characterize the region around that school.
- If you understand how counties work in the US, and you are analyzing other data that has county variables (e.g., data from hospitals located in certain counties), then “hooking on” county-level estimates is a great way to add value to your data from the census.
Cons:
- You really have to understand the US in terms of geographic regions in order to utilize the data. You need to understand states, counties, MSAs, census districts, and other regional definitions.
- Some data are suppressed for privacy reasons.
- It’s great that there are so many datasets and so much data available, but many are hard to understand. Beyond the simple analysis, it will take you some time to get to know what exactly is available, and what you can use for your purposes.
Resources:
- If you click below, you will be directed to the census online table-builder. However, there are other data products you can explore from the census.

Description: The International Institute for Democracy and Electoral Assistance (International IDEA) supports democracy worldwide, so it makes this online query platform available. You select the country, and then choose which metric you want, with “voter turnout” being the focus. As you can imagine, “voter turnout” has a numerator and a denominator, and other associated metrics, so you can query for those, too.
Pros:
- Very easy to start using the platform. Very intuitive user interface.
- Would not be difficult to design an ecological/correlational study with the data based on some sort of hypothesis about voter turnout and country-level policy.
- Trustable, updated and well-documented.
Cons:
- Data on many metrics are missing from countries that are probably the most important to track for democracy purposes.
- Political systems are different in every country, so it actually is hard to compare.
- Only reflects national elections – but even those can be complicated (e.g., president vs. parliamentary election).
- Not obvious how to download datasets (for putting in statistical software).

Description: This dataset is a result of a university grant. It is an extensive database that includes detailed information on all national “election events” from 1945 to 2020.
Pros:
-
Extremely thorough and comprehensive data and documentation.
-
Data structured to be used in a statistical program (like R or SAS).
-
Dataset subject of peer-reviewed article and extensively vetted.
Cons:
-
Requires extensive study of different countries and the data available to formulate a research aim.
-
Must apply to obtain access to dataset.
Resources:
- Access the online codebook.

Formal name:United States Department of Agriculture (USDA) Forest Service National Datasets.
Description: These are mainly GIS shape and related files to provide mapping capabilities. These include sides and regions. There are also metadata files.
Pros:
- You can download the datasets directly from the web site.
- Can be useful in environmental studies, especially if combined with other GIS files for the same regions.
Cons:
- You already need to have a lot of subject matter expertise in order to use these files.
- You need to be able to use GIS shape files and the ESRI database, as well as have advanced knowledge of US geography, forestry, policy, and related issues.
Last updated July 15, 2023. Revised banners June 17, 2023. Added more datasets October 15, 2023. Added link to NHANES blog post November 2, 2023. Added videos January 19, 2024. Added NCHS on March 17, 2024. Added MEPS and USDA and updated banners June 9, 2024.
Read all of our data science blog posts!

Confidence Intervals are for Estimating a Range for the True Population-level Measure
Confidence intervals (CIs) help you get a solid estimate for the true population measure. Read [...]
1 Comment
Jun
Continuous Variable? You Can Categorize it!
Continuous variable categorized can open up a world of possibilities for analysis. Read about it [...]
184 Comments
Jun

Delete if the Row Meets Criteria? Do it in SAS!
Delete if rows meet a certain criteria is a common approach to paring down a [...]
May


Chi-square Test: Insight from Using Microsoft Excel
Chi-square test is hard to grasp – but doing it in Microsoft Excel can give [...]
May

Identify Elements of Research in Scientific Literature
Identify elements in research reports, and you’ll be able to understand them much more easily. [...]
May

Design the Most Useful Time Periods for Your Conversions
Time periods are important when creating a time series visualization that actually speaks to you! [...]
Apr

Apply Weights? It’s Easy in R with the Survey Package!
Apply weights to get weighted proportions and counts! Read my blog post to learn how [...]
Nov

Make Categorical Variable Out of Continuous Variable
Make categorical variables by cutting up continuous ones. But where to put the boundaries? Get [...]
Nov

Remove Rows in R with the Subset Command
Remove rows by criteria is a common ETL operation – and my blog post shows [...]
Oct

CDC Wonder for Studying Vaccine Adverse Events: The Shameful State of US Open Government Data
CDC Wonder is an online query portal that serves as a gateway to many government [...]
Jun

AI Careers: Riding the Bubble
AI careers are not easy to navigate. Read my blog post for foolproof advice for [...]
Jun

Descriptive Analysis of Black Friday Death Count Database: Creative Classification
Descriptive analysis of Black Friday Death Count Database provides an example of how creative classification [...]
Nov

Classification Crosswalks: Strategies in Data Transformation
Classification crosswalks are easy to make, and can help you reduce cardinality in categorical variables, [...]
Nov

FAERS Data: Getting Creative with an Adverse Event Surveillance Dashboard
FAERS data are like any post-market surveillance pharmacy data – notoriously messy. But if you [...]
4 Comments
Nov

Dataset Source Documentation: Necessary for Data Science Projects with Multiple Data Sources
Dataset source documentation is good to keep when you are doing an analysis with data [...]
Nov

Joins in Base R: Alternative to SQL-like dplyr
Joins in base R must be executed properly or you will lose data. Read my [...]
Nov

NHANES Data: Pitfalls, Pranks, Possibilities, and Practical Advice
NHANES data piqued your interest? It’s not all sunshine and roses. Read my blog post [...]
Nov

Color in Visualizations: Using it to its Full Communicative Advantage
Color in visualizations of data curation and other data science documentation can be used to [...]
Oct

Defaults in PowerPoint: Setting Them Up for Data Visualizations
Defaults in PowerPoint are set up for slides – not data visualizations. Read my blog [...]
Oct
Text and Arrows in Dataviz Can Greatly Improve Understanding
Text and arrows in dataviz, if used wisely, can help your audience understand something very [...]
Oct

Shapes and Images in Dataviz: Making Choices for Optimal Communication
Shapes and images in dataviz, if chosen wisely, can greatly enhance the communicative value of [...]
Oct

Table Editing in R is Easy! Here Are a Few Tricks…
Table editing in R is easier than in SAS, because you can refer to columns, [...]
Aug

R for Logistic Regression: Example from Epidemiology and Biostatistics
R for logistic regression in health data analytics is a reasonable choice, if you know [...]
272 Comments
Aug

Connecting SAS to Other Applications: Different Strategies
Connecting SAS to other applications is often necessary, and there are many ways to do [...]
Jul

Portfolio Project Examples for Independent Data Science Projects
Portfolio project examples are sometimes needed for newbies in data science who are looking to [...]
Jul

Project Management Terminology for Public Health Data Scientists
Project management terminology is often used around epidemiologists, biostatisticians, and health data scientists, and it’s [...]
Jun

Rapid Application Development Public Health Style
“Rapid application development” (RAD) refers to an approach to designing and developing computer applications. In [...]
Jun

Understanding Legacy Data in a Relational World
Understanding legacy data is necessary if you want to analyze datasets that are extracted from [...]
Jun

Front-end Decisions Impact Back-end Data (and Your Data Science Experience!)
Front-end decisions are made when applications are designed. They are even made when you design [...]
Jun

Reducing Query Cost (and Making Better Use of Your Time)
Reducing query cost is especially important in SAS – but do you know how to [...]
Jun

Curated Datasets: Great for Data Science Portfolio Projects!
Curated datasets are useful to know about if you want to do a data science [...]
May

Statistics Trivia for Data Scientists
Statistics trivia for data scientists will refresh your memory from the courses you’ve taken – [...]
Apr

Management Tips for Data Scientists
Management tips for data scientists can be used by anyone – at work and in [...]
Mar

REDCap Mess: How it Got There, and How to Clean it Up
REDCap mess happens often in research shops, and it’s an analysis showstopper! Read my blog [...]
Mar

GitHub Beginners in Data Science: Here’s an Easy Way to Start!
GitHub beginners – even in data science – often feel intimidated when starting their GitHub [...]
Feb
ETL Pipeline Documentation: Here are my Tips and Tricks!
ETL pipeline documentation is great for team communication as well as data stewardship! Read my [...]
Feb

Benchmarking Runtime is Different in SAS Compared to Other Programs
Benchmarking runtime is different in SAS compared to other programs, where you have to request [...]
Dec

End-to-End AI Pipelines: Can Academics Be Taught How to Do Them?
End-to-end AI pipelines are being created routinely in industry, and one complaint is that academics [...]
Nov

Referring to Columns in R by Name Rather than Number has Pros and Cons
Referring to columns in R can be done using both number and field name syntax. [...]
Oct

The Paste Command in R is Great for Labels on Plots and Reports
The paste command in R is used to concatenate strings. You can leverage the paste [...]
Oct

Coloring Plots in R using Hexadecimal Codes Makes Them Fabulous!
Recoloring plots in R? Want to learn how to use an image to inspire R [...]
5 Comments
Oct

Adding Error Bars to ggplot2 Plots Can be Made Easy Through Dataframe Structure
Adding error bars to ggplot2 in R plots is easiest if you include the width [...]
Oct

AI on the Edge: What it is, and Data Storage Challenges it Poses
“AI on the edge” was a new term for me that I learned from Marc [...]
Jun

Pie Chart ggplot Style is Surprisingly Hard! Here’s How I Did it
Pie chart ggplot style is surprisingly hard to make, mainly because ggplot2 did not give [...]
5 Comments
Apr

Time Series Plots in R Using ggplot2 Are Ultimately Customizable
Time series plots in R are totally customizable using the ggplot2 package, and can come [...]
Apr

Data Curation Solution to Confusing Options in R Package UpSetR
Data curation solution that I posted recently with my blog post showing how to do [...]
Apr

Making Upset Plots with R Package UpSetR Helps Visualize Patterns of Attributes
Making upset plots with R package UpSetR is an easy way to visualize patterns of [...]
11 Comments
Apr

Making Box Plots Different Ways is Easy in R!
Making box plots in R affords you many different approaches and features. My blog post [...]
Mar

Convert CSV to RDS When Using R for Easier Data Handling
Convert CSV to RDS is what you want to do if you are working with [...]
Mar

GPower Case Example Shows How to Calculate and Document Sample Size
GPower case example shows a use-case where we needed to select an outcome measure for [...]
Feb

Querying the GHDx Database: Demonstration and Review of Application
Querying the GHDx database is challenging because of its difficult user interface, but mastering it [...]
Feb

Variable Names in SAS and R Have Different Restrictions and Rules
Variable names in SAS and R are subject to different “rules and regulations”, and these [...]
Feb

Referring to Variables in Processing Data is Different in SAS Compared to R
Referring to variables in processing is different conceptually when thinking about SAS compared to R. [...]
Jan

Counting Rows in SAS and R Use Totally Different Strategies
Counting rows in SAS and R is approached differently, because the two programs process data [...]
Jan

Native Formats in SAS and R for Data Are Different: Here’s How!
Native formats in SAS and R of data objects have different qualities – and there [...]
Jan

SAS-R Integration Example: Transform in R, Analyze in SAS!
Looking for a SAS-R integration example that uses the best of both worlds? I show [...]
Dec
Dumbbell Plot for Comparison of Rated Items: Which is Rated More Highly – Harvard or the U of MN?
Want to compare multiple rankings on two competing items – like hotels, restaurants, or colleges? [...]
2 Comments
Sep
Data for Meta-analysis Need to be Prepared a Certain Way – Here’s How
Getting data for meta-analysis together can be challenging, so I walk you through the simple [...]
Jul

Sort Order, Formats, and Operators: A Tour of The SAS Documentation Page
Get to know three of my favorite SAS documentation pages: the one with sort order, [...]
Nov

Confused when Downloading BRFSS Data? Here is a Guide
I use the datasets from the Behavioral Risk Factor Surveillance Survey (BRFSS) to demonstrate in [...]
2 Comments
Oct
Doing Surveys? Try my R Likert Plot Data Hack!
I love the Likert package in R, and use it often to visualize data. The [...]
3 Comments
Oct
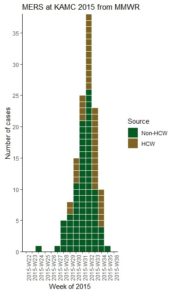
I Used the R Package EpiCurve to Make an Epidemiologic Curve. Here’s How It Turned Out.
With all this talk about “flattening the curve” of the coronavirus, I thought I would [...]
Mar
Which Independent Variables Belong in a Regression Equation? We Don’t All Agree, But Here’s What I Do.
During my failed attempt to get a PhD from the University of South Florida, my [...]
Aug
Curated datasets are useful to know about if you want to do a data science portfolio project on your own. I made this blog post for our group mentoring program. Check out the ones I am promoting on my blog!