
WISE Summit 2023 at Northeastern University was the biggest and best one so far! I was honored to lead a business intelligence workshop, as I talk about in my blog post.
Tag Archives: syllabus data science

06
Jun
Jun
“AI on the edge” was a new term for me that I learned from Marc Staimer, founder of Dragon Slayer Consulting, who was interviewed in a podcast. Marc explained how AI on the edge poses a data storage problem, and my blog post proposes a solution!

28
Jan
Jan
Referring to variables in processing is different conceptually when thinking about SAS compared to R. I explain the differences in my blog post.
30
Jul
Jul
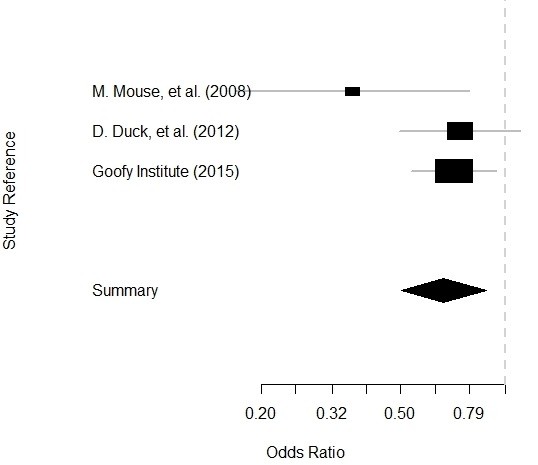
Getting data for meta-analysis together can be challenging, so I walk you through the simple steps I take, starting with the scientific literature, and ending with a gorgeous and evidence-based Forrest plot!

20
Oct
Oct
SAS is known for big data and data warehousing, but how do you actually design and build a SAS data warehouse or data lake? What datasets do you include? How do you transform them? How do you serve warehouse users? How do you manage your developers? This book has your answers!