
Are you aware of the ASPPH as a public health organization, but you just don’t know what it does, or how it fits into the bigger picture? I give a quick explainer of the ASPPH and its role in public health education.
Author Archives: Monika Wahi

23
Jul
Jul
Want to know what AHRQ stands for, what it does, and how all that relates to US public health? AHRQ is a main player in public health – even though it is technically supposed to be focused on healthcare.

21
Jul
Jul
Curious about the American Public Health Association (APHA) – what it does, and where it fits into the bigger picture of public health organizations? I delve into these topics, and explain how you can get involved.
Quality Assurance/Quality Improvement (QA/QI)
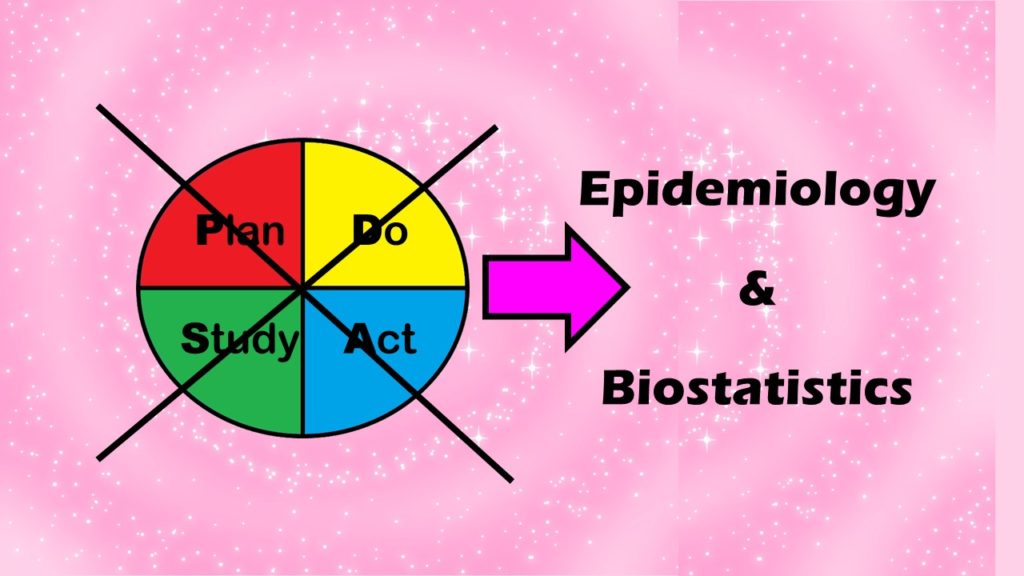
Recommended Model for QA/QI in Healthcare: Epidemiology and Biostatistics, not PDSA! Part 5 of 5
14
Jul
Jul
I describe the three steps of my alternative model to the Plan-Do-Study-Act (PDSA) model for quality assurance/quality improvement (QA/QI) in healthcare.
Quality Assurance/Quality Improvement (QA/QI)
“Bad Blood” Highlights the Issues with No Administrative Barrier between Research and Clinical Data: Part 5 of 5

12
Jul
Jul
Read my last post in a series on data-related misconduct at startup Theranos outlined in the book, “Bad Blood”, where I discuss their lack of administrative barrier between research and clinical data.
Quality Assurance/Quality Improvement (QA/QI)
Alternative to the PDSA Model for QA/QI in Healthcare? Old-fashioned Epidemiology and Biostatistics! Part 4 of 5
07
Jul
Jul
Want an alternative to the Plan-Do-Study-Act (PDSA) model for quality assurance/quality improvement (QA/QI) in healthcare? I recommend approaching QA/QI a different way, by thinking about the various functions of the QA/QI department.
Quality Assurance/Quality Improvement (QA/QI)
“Bad Blood” is a Lesson in How Bad Leadership Leads to Bad Data: Part 4 of 5

05
Jul
Jul
As a data science leader, what should you put in place so your organization doesn’t end up a data mess like startup Theranos? This blog posts provides guidance.
30
Jun
Jun
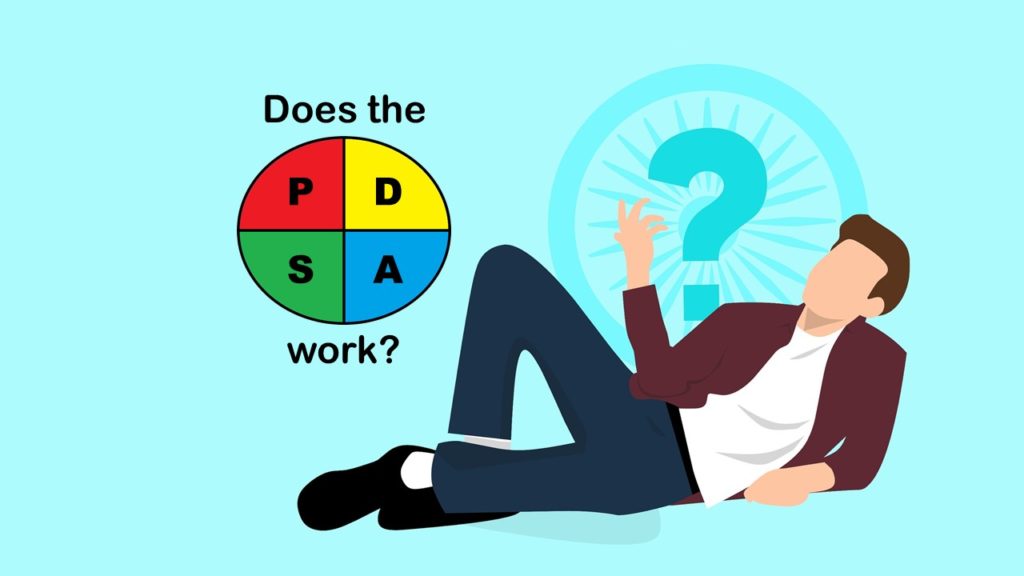
The Plan-Do-Study-Act model is promoted for quality assurance/quality improvement in healthcare. But does it have any peer-reviewed evidence base behind it? I examine that in this blog post.
Quality Assurance/Quality Improvement (QA/QI)
“Bad Blood” Shows how Theranos was an Abject Failure in Data Stewardship: Part 3 of 5

28
Jun
Jun
The book “Bad Blood” describes the fall of startup unicorn Theranos, but also provides insight into the company’s abject failure at data stewardship, which I talk about in this blog post.
Quality Assurance/Quality Improvement (QA/QI)
“Bad Blood” Demonstrates how a Lack of Product Description Leads to Data Science Misconduct: Part 2 of 5

25
Jun
Jun
This blog post talks about how lack of product description led to data-related misconduct at Theranos, because they could never nail down exactly what they were trying to do.